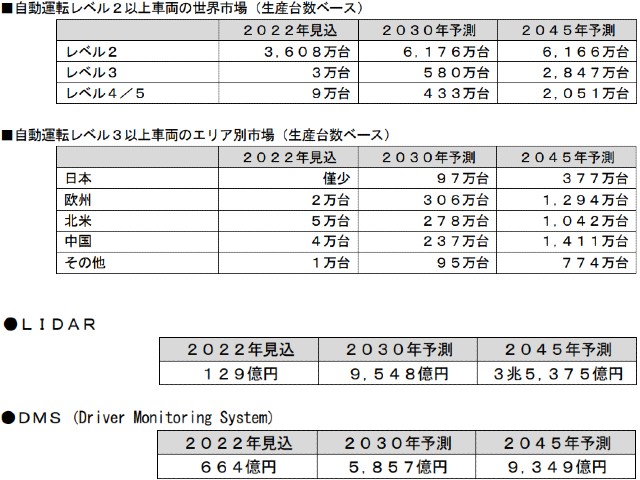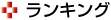
名古屋大学は,徳島大学,アイシン精機と共同で,自動運転オープンソースソフトウェア「Autoware」を利用し,音声認識・顔画像認識・ジェスチャー認識を組み合わせたマルチモーダルインタフェースで,自動車を直観的に操作するシステムを開発した(ニュースリリース)。
近年,自動運転車の研究開発は急速に進展し,日米で公道において走行実験が行なわれるようになった。しかし,自動運転のための周囲のセンシングや車の制御などの技術は進展しているものの,実際に一般の人が自動運転車に乗り込み,目的の場所に移動するために,どのように「自動運転車を操作する」のかについての検討はあまり行なわれてこなかった。
自動運転車が真に社会に浸透し,一般の人が容易に利用できるようにするためには,自動運転車と人とのコミュニケーションが必要。その自動運転車のインタフェースの一つの理想形がタクシーだとする。
乗客は運転手に行き先を告げ,必要に応じて曲がる場所などを伝え,行き先に来たら停まってもらう,このようなやり取りは,音声による対話を中心に,ジェスチャーなどを交えながら交わされる。このやり取りを自動運転車との間でできないかという期待が持たれてきた。
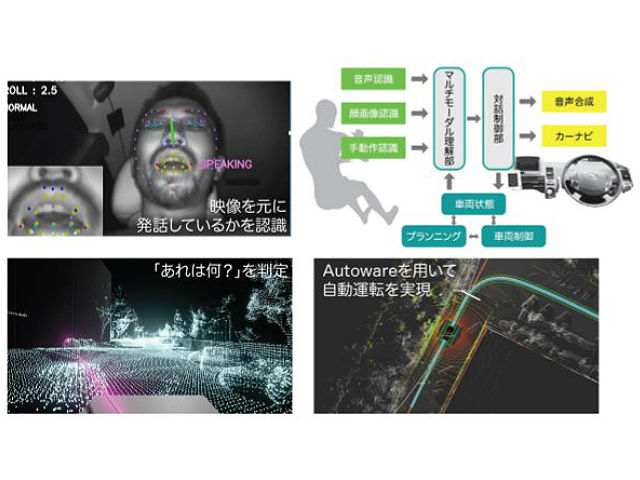
今回研究グループは,音声対話を中心とし,ジェスチャや視線も情報伝達手段として用いることのできる,「人対人のコミュニケーション」から発想を得た「自動運転車用マルチモーダルインタフェースシステム」の開発に取り組んだ。
このシステムは,人(ユーザー)の音声,ジェスチャー,視線などはそれぞれ音声認識,深度センサー,映像処理を用いて認識をする。例えば,ユーザーが「右に曲がって」と発声すれば,システムはユーザの意図に従って,自動車に右に曲がるように制御を依頼し,実際に自動車は右に曲がる。
一方,音声とジェスチャーや視線を同時に用いる場合,それらの入力は並行して行なわれるので,ユーザーが自動運転車に伝えようとする「意図」はそれらを統一して理解する必要がある。例えば,ある建物を見ながら「あれは何?」と尋ねれば,「あれ」と言っている時にユーザーが見ている建物の名称を答えてほしい,という意図の理解が必要。
このような各入力手段(モダリティ)の時間的関係も考慮しながら,マルチモーダル理解を行ない,その意図に応じて応答し,車を制御するマルチモーダルインターフェースを備えた自動運転車を開発・実現した。
研究グループは今後,自動運転車に限らず,機械と人間の協調・共生を考えた場合,マルチモーダルインターフェースは自然で使いやすいインターフェースとして取り入れられていくと期待している。