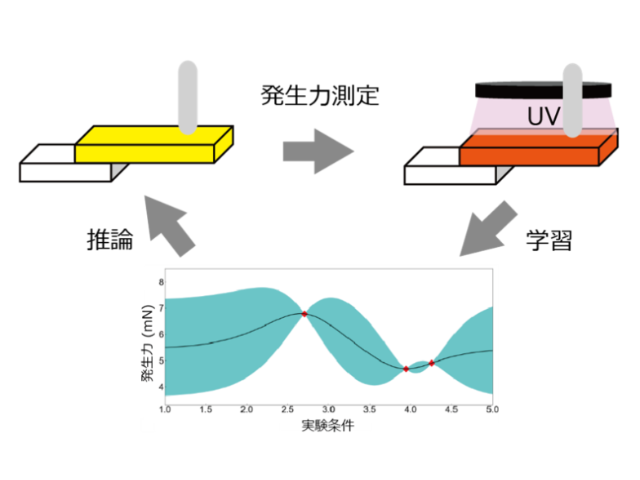
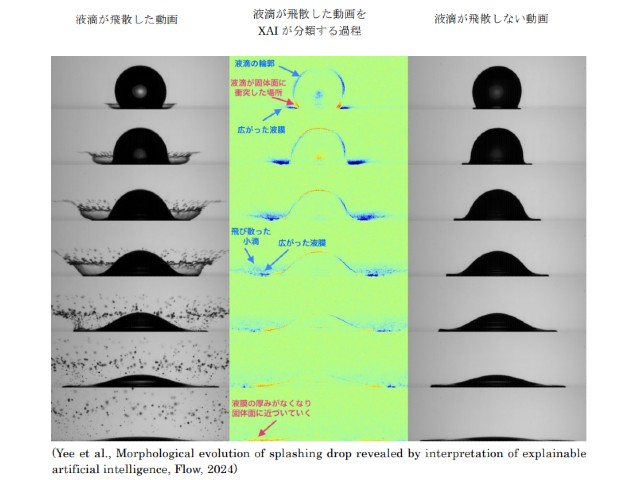
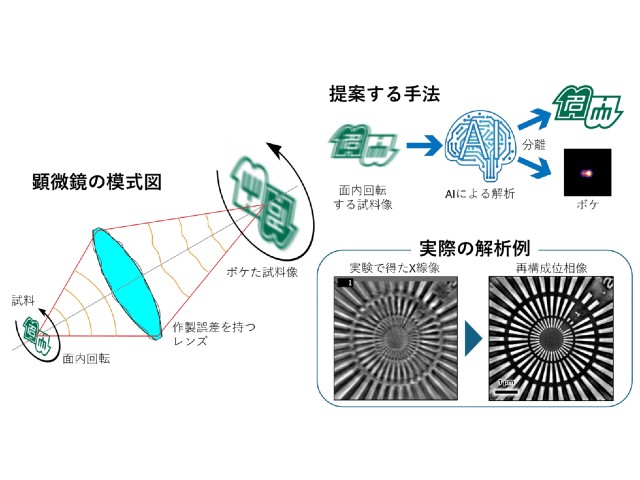
 早稲田大学の研究グループは,多彩な形式の材料科学のデータを単一の人工知能(AI)に学習させる手法を開発した(ニュースリリース)。
早稲田大学の研究グループは,多彩な形式の材料科学のデータを単一の人工知能(AI)に学習させる手法を開発した(ニュースリリース)。
近年のAI技術の進歩を背景に,これを革新材料の探索に応用するマテリアルズ・インフォマティクス(MI)の研究が進められている。しかしながら,現在のAIの水準は“知能”と呼ぶにはほど遠い。課題の一つは,材料科学で使われるAIの予測モデルは原則として1つのデータベースや概念しか学習出来ない点だった。
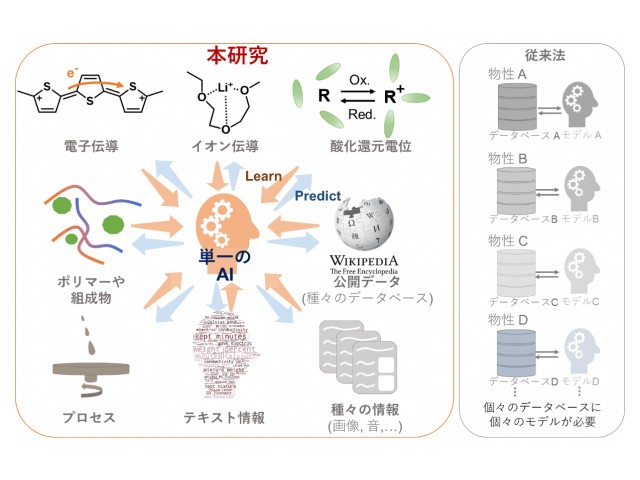
ヒトは多彩な分野(言語,数学,化学,物理,人文,社会科学など)を知識として取り入れ,それらを統合した上で総合的な判断を下すが,AIに対して異なる概念を学習させるのは容易ではない。そこで研究グループは,多彩な材料データベースや異なる物性値を単一の学習モデルに認識・学習させ,材料科学に関する広範な知識をAIに付与する作業に挑戦した。
グラフ構造と呼ばれるフォーマットに着眼し,種々のデータベースを共通書式に変換する手法を開発した。従来の材料データベースはExcelのような表形式が大半だったが,通常の学習モデルは単一の構造の表形式データしか受け付けず,異種データベースの学習が困難だった。
一方,研究グループは全データを共通書式のグラフ構造に変換し,専用の学習モデルに入力することで,原理的にあらゆるデータベースを学習可能にした。
この手法の導入により,単一のAIで40種類以上の物性,数千以上の化合物,数百以上のプロセス情報を学習・予測させることが出来た。特筆すべき例は,透明ディスプレー等への応用も期待されるPEDOT-PSSと呼ばれる導電性ポリマーの性能予測において,AIはフィルムの製法をもとに1万倍も増減する可能性のある導電性を化学実験の熟練者並の精度で予測できた。
MIのボトルネックであるデータ収集も,例えばWikipediaのような膨大な公知のビッグデータ中にある多彩な化合物の情報を入力し,“化学の知識を身につけさせ”つつ,目的のデータベースと同時学習させることで,後者の学習精度を上げられるという。
種々の分野の多彩な背景知識を与えて“AIの経験と勘を磨く”という手法は,“万能AI”を導く一つの道筋となる可能性があるという。オープンアクセス論文や特許などの材料科学に関する膨大な公開データを自動収集し,学習させるとどのような景色が見えてくるのか,また最近注目されている逆問題を解くためのより洗練された方法論などを今後明らかにしていくとしている。