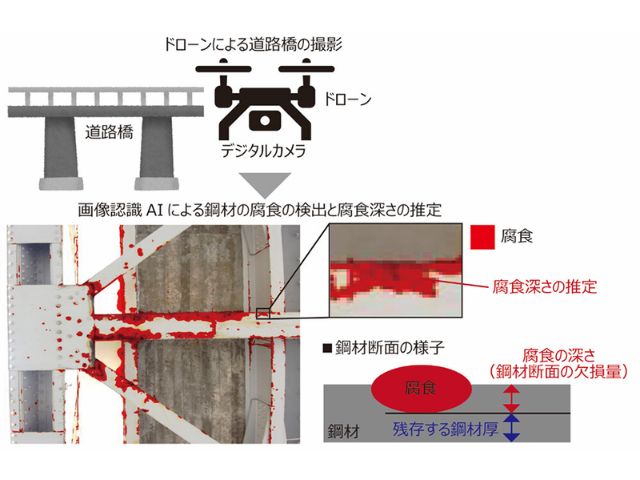
産業技術総合研究所(産総研)は,画像中の物体を認識する画像識別に加えて,物体の範囲情報など画像中の詳細内容を把握できる画像領域分割を行なうAIの学習に成功し,画像領域分割を含む基礎的な視覚に関する能力を持つAIを実現した(ニュースリリース)。
画像中の物体を認識する画像識別だけではなく,物体の位置情報を含む画像中の詳細内容を把握できる画像領域分割は,大量の実画像に人間が手作業で教師ラベルを付与することで画像データセットを構成し,AIが学習することで視覚能力を獲得する。
しかし,人間による教師ラベル付けには1画像あたり数十分の時間を要するとも言われており,産業現場によっては必要な画像の収集自体も難しく,膨大な人的コストを要するという課題があった。
さらに,現在,研究現場で使用されている画像認識AIは,学習した画像データセットの実画像によってプライバシーの侵害や,攻撃的ラベルを含むなど倫理面での問題が生じる懸念もあり,商用目的での利用が難しい。
研究グループはこれまで,数理モデルで生成した学習用の画像に,画像を識別した教師ラベルまで自動で生成するタスクまで開発に成功している。今回,より産業応用に特化したタスクとして,画素ごとの位置情報を生成できる画像領域分割のタスクを同時に学習できるようになった。
これにより,膨大な人的コストを抑えるとともに,実画像データを使用することなく,画像領域分割の事前学習モデルを構築できる。
画像領域分割技術を実現したことで,産業応用先のタスクに応じて画像や教師ラベルを柔軟に変化できる。加えて,画像,教師ラベルともに数理モデルから生成し,画像データセットを構築可能な性質上,プライバシー保護など倫理問題を気にせず容易にAIを構築できる。
また,従来のデータセットと同様に物体の種類ごとに領域を色分けした教師データを生成できることがわかった。データセットは,元となる数理モデルを柔軟に変更できるため,適応する産業現場で求められるデータの性質に合わせて,学習データにおける形状やテクスチャ,色などの見た目をパラメータで変更できる。
画像領域分割データセットの構成要素を変化させることで,事前学習データセットの性質が変化し,どのような画像の領域分割が得意なのかが異なっていく。多様な画像領域分割データセットのタスクに応じてパラメータをあらかじめカスタマイズすることで,最も性能向上につながる事前学習を実行できる。
研究グループは,今後は,人間の膨大な量の教師ラベル付けにコストを要する画像領域分割に対してこの成果を適用していくとしている。