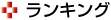 東京工業大学は,胸装着型の小型超魚眼カメラで撮影した映像を深層学習ネットワークで学習することで,利用者の身体形状を正確に推定するモーションキャプチャ技術を開発した。さらに,身体形状と同時に頭部の向きを推定し,一人称視点映像を合成することを可能にした(ニュースリリース)。
東京工業大学は,胸装着型の小型超魚眼カメラで撮影した映像を深層学習ネットワークで学習することで,利用者の身体形状を正確に推定するモーションキャプチャ技術を開発した。さらに,身体形状と同時に頭部の向きを推定し,一人称視点映像を合成することを可能にした(ニュースリリース)。
モーションキャプチャ技術は,スポーツ科学,医療,アニメーション制作などで広く用いられており,現在は光学式と慣性式が主流となっている。
光学式モーションキャプチャシステムでは,同期させた複数台の高性能カメラを部屋の天井や壁に固定して,動作計測を行なう。しかしこのシステムは,利用者が広い空間を移動する場合には適用できなかった。また,利用者はマーカーの付いたスーツを着用しなければならず,利便性も低かった。
一方,慣性式モーションキャプチャシステムでは,各関節部分に慣性センサーを付けたスーツを着用し,動作計測を行なう。運動範囲は広いが,周辺に金属があると測定誤差が生じる。また,スーツ着用の手間がかかる点も光学式システムと同じで,光学式,慣性式ともに,導入コストは数百万円以上する。
近年,利用者に小型カメラを装着し,撮影した映像を深層学習ネットワークに学習させることで,利用者の動作推定をする研究が行なわれている。しかし,これまで開発された手法では,利用者の頭部にカメラを装着するために装着感が悪く,カメラの画角が小さいため,上肢部分のみの推定に限定されていた。
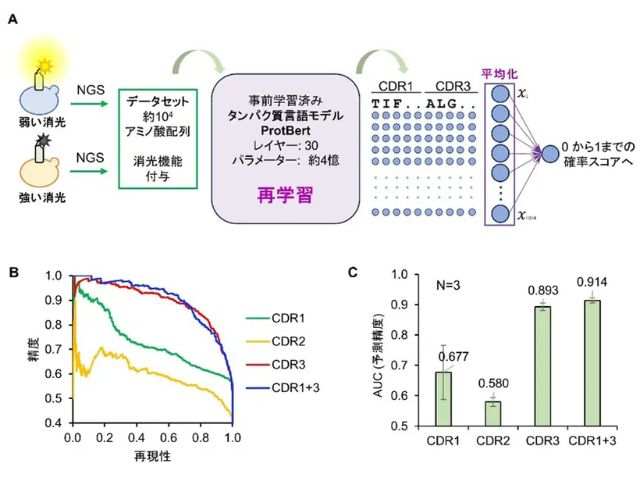
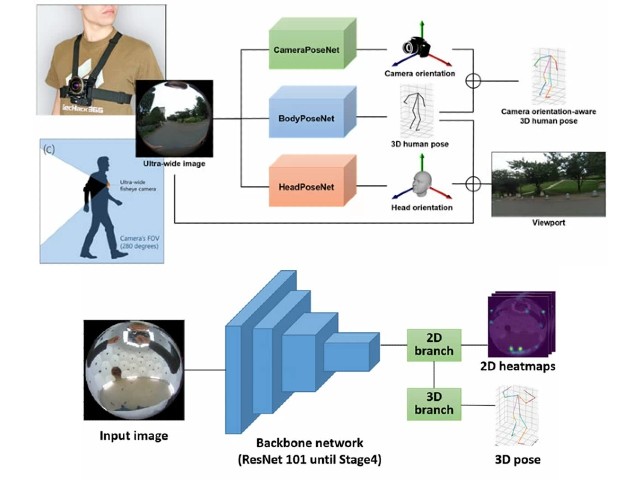
今回開発したモーションキャプチャシステムでは,利用者の胸に画角280度の超魚眼カメラを装着する。この超魚眼カメラで撮影した映像には,身体形状の推定に必要な,利用者の頭部,両手,両足が全て映っている。この超魚眼映像を入力とし,撮影時の3次元姿勢と一人称視点を出力とする深層学習ネットワークを新たに設計した。
深層学習のためには,人工データと実データのデータセットが必要になる。研究では,3次元CGを用いて作成した680,000枚の超魚眼映像と3次元姿勢からなる人工データと,実際に撮影した16,000枚の超魚眼映像と3次元姿勢からなる実データを用意した。
評価実験の結果,人工データでの各関節における平均誤差は,上肢部分で24.6mm,下肢部分で62.5mm,全体として43.6mmとなった。一方,実データでは平均誤差が84.9mmとなったが,これは今後のデータセットの拡充で精度向上が期待できるという。
また,このモーションキャプチャシステムは,カメラの小型化によって利便性が向上するとともに,コストダウンも可能だとしている。