 高エネルギー加速器研究機構(KEK)と東京理科大学は,統計数理研究所と共同で,機械学習を用いて物質・材料研究に必要不可欠なX線吸収スペクトルの解析を自動化・高効率化する手法を開発した(ニュースリリース)。
高エネルギー加速器研究機構(KEK)と東京理科大学は,統計数理研究所と共同で,機械学習を用いて物質・材料研究に必要不可欠なX線吸収スペクトルの解析を自動化・高効率化する手法を開発した(ニュースリリース)。
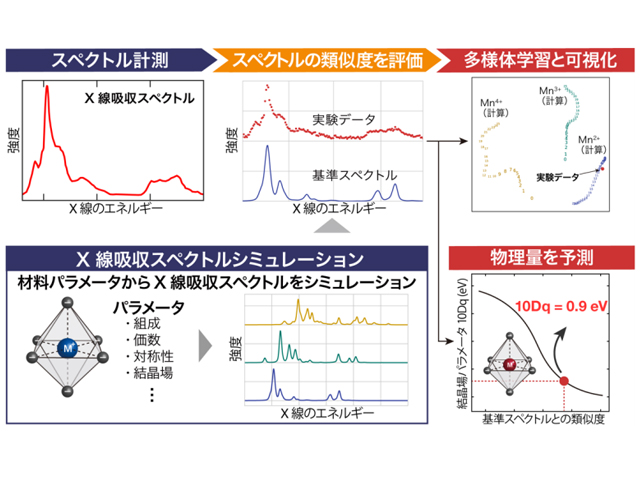
物質中の電子状態を調べるために,物質にX線を照射し,その吸収量を測定するXASが広く用いられている。ここではデータ解析によってスペクトルに対応する物理量(材料パラメータ)を推定し,それを元に議論がなされるが,従来は専門家が経験に基づいて,実験スペクトルの微妙な形状変化をシミュレーションや文献と比較することにより,物理量を推定してきた。
この方法では解析者の主観が除けない上に,解析作業にかかる人的・時間的コストの高さが問題となる。一方でX線吸収スペクトル計測の効率化は急速に進展しており,現在では24時間で1万本以上のXASスペクトルを取得できるため,データ解析の自動化や効率化が強く望まれていた。
研究グループは,機械学習の基礎技術であるデータの類似度の概念および,機械学習の一種である多様体学習に着目し,X線吸収スペクトル解析への応用に着手した。材料開発における機械学習の応用はマテリアルズインフォマティクス(MI)と呼ばれる研究領域で,近年急速な発展が続いている。
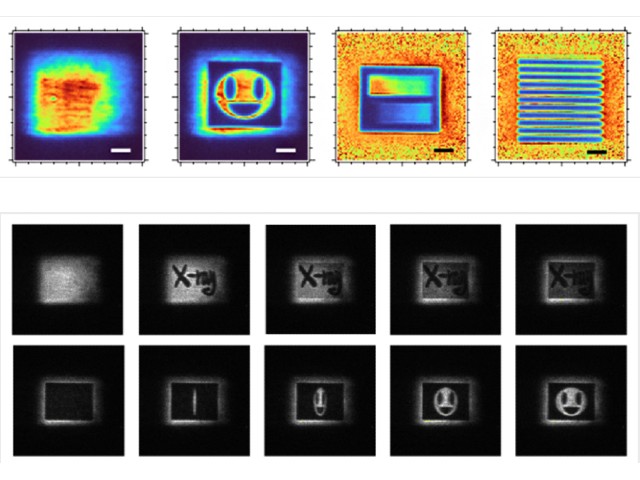
研究では,データ解析における本質的な問題点を議論し,2つのスペクトルがどのくらい似ているのかを示す指標である類似度が定まっていないことから,スペクトル形状の微妙な変化を捉えて物理量を解析するために適した類似度について検討した。
この結果,専門家による解析と同程度の精密さで,スペクトルに対応した物理量を予測できることを実証した。解析は自動かつ高速に行なわれ,スペクトル1本あたりの解析時間は0.1ミリ秒程度。さらに,適切な類似度を用いることで,従来は困難であった非常にノイズの多いデータや分解能の悪い装置で得られたデータの解析も,自動で精度良く行なう可能性が示唆された。
データの類似度の適切な選定は,機械学習をはじめとしたデータ解析の基礎であり,研究では計測データの類似度の重要性と有用性を示すことができた。
この成果によって,X線吸収スペクトルを自動かつ定量的に解析することが可能となり,ハイスループット計測と組み合わせることで,材料開発サイクルの飛躍的な加速につながることが期待されるという。加えて,ノイズの多いデータの解析を可能にしたことで,測定時間の大幅な短縮につながるほか,不安定な物質や超高速現象の計測や解析への応用が見込まれ,新奇な物理現象の発見と理解への波及が期待されるとしている。