産業技術総合研究所(産総研)は,画像基盤モデルを使用して少量の内視鏡画像の学習から高精度に診断する膀胱内視鏡診断支援AIを開発した(ニュースリリース)。
現在,医療分野において画像診断を支援するAIの開発が進んでいるが,医療現場で実際に画像診断支援AIが活用されている領域は限られている。特に患者数や検査数の少ない疾病や希少症例では教師データの収集が難しいため,画像診断支援AIの適用が困難だった。
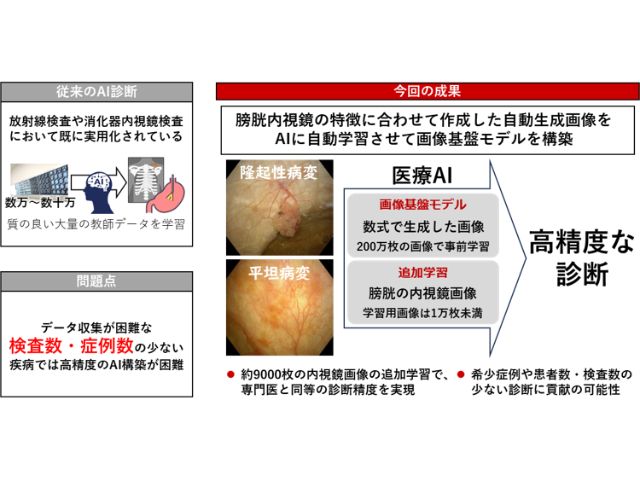
研究グループは,膀胱内視鏡画像に映る膀胱内壁の特徴を考慮し,特徴の異なる2種類の数式から自動生成した大規模画像データセットを事前学習する方法を考案し,膀胱内視鏡診断支援のための画像基盤モデルの開発に至った。
この事業では,この膀胱内視鏡画像における膀胱粘膜の変化に着目し,これらの特徴を認識する機能を有する画像基盤モデルを構築することを目指した。
具体的には,表面の質感の特徴を持つFractalDBにより生成した画像100万枚と,輪郭形状の特徴を持つVisual Atomsにより生成した画像100万枚を合わせた大規模画像データセット200万枚を用いて,画像分類AIのトップモデルであるVision Transfomer(ViT)を事前学習し,膀胱内視鏡画像向けの画像基盤モデルを構築した。
さらに,この画像基盤モデルに対し,病変の1259枚と,正常の7553枚,合計8812枚の膀胱内視鏡画像の追加学習により診断支援AIモデル(MixFDSL-2k)を構築した。
開発したMixFDSL-2kは,感度94.3%,特異度99.4%,正解率98.3%を達成した。この診断精度は,事前学習をしなかった場合(事前学習なし)と比較して感度は+16.1%,特異度は+9.3%,正解率は+10.6%向上した。
また,事前学習に広く使用されているデータセットであるImageNet-21kとImageNet-1kを事前学習に用いた場合の診断精度も超えたことを確認した。さらに,泌尿器科勤務経験が5年以上の専門医8名に,同じ膀胱内視鏡画像422枚を1枚ずつ見せてAIと同じタスクを試したところ,8名の平均感度,平均特異度,平均正解率のいずれも開発した診断支援AIが上回り,専門医に匹敵する結果となった。
研究グループは,今後,診断対象領域に合わせて画像基盤モデルを開発し,膀胱内視鏡以外にも教師データの収集が困難な医療分野への適用を進めていく予定だとしている。