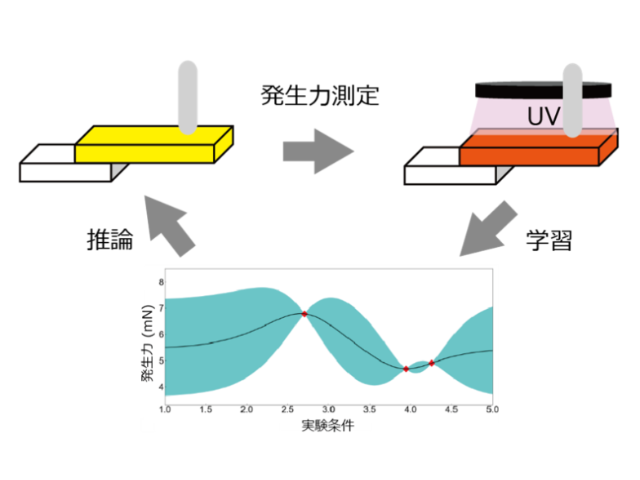
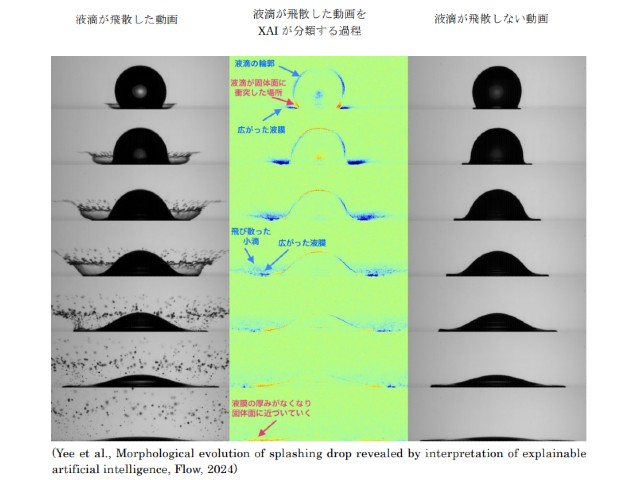
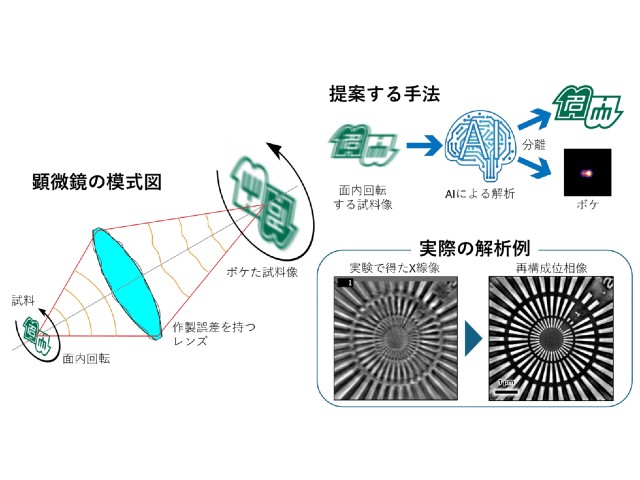
 東京大学の研究グループは,頭部装着型カメラにより記録された「一人称視点映像」から,人の視線の動きをこれまでにない精度で予測する手法を開発した(ニュースリリース)。
東京大学の研究グループは,頭部装着型カメラにより記録された「一人称視点映像」から,人の視線の動きをこれまでにない精度で予測する手法を開発した(ニュースリリース)。
人の詳細な行動の理解には,人がいつ何に注意を向けているのかを知ることが重要となる。映像から人の視線がどう動くかを予測できれば,視線計測デバイスなどの特殊な装置を用いることなく人が何をどう見ているのかを知ることが可能となる。
一方,人の視線の動きはその人物が行っている作業に強く依存することが知られていたが,既存の一人称視点映像からの視線予測手法では,この作業依存性が考慮されていなかった。
今回,例えば人がキッチンで料理をする中で,どのタイミングでどのような物からどのような物へ視線を動かすのかを,その作業中に記録した一人称視点映像と視線データから事前に学習することにより,新たな映像から,これまでにない精度で視線移動を予測することに成功した。
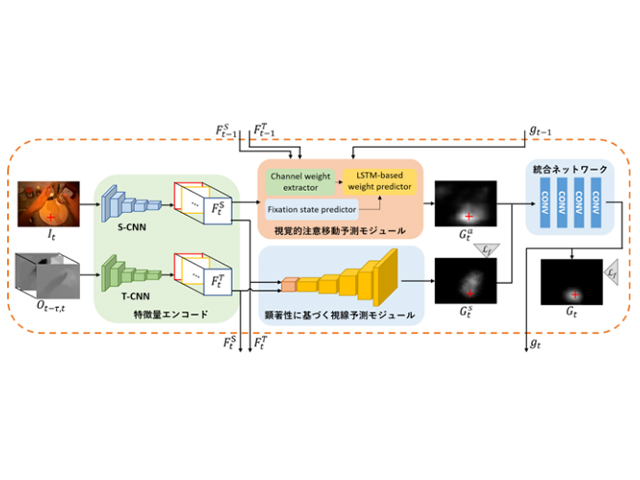
提案手法は,前段のS-CNN(映像の各カラー画像フレームを入力とする畳み込み型ニューラルネットワーク)とT-CNN(映像から計算されたオプティカルフローと呼ばれる動き成分を入力とする畳み込みニューラルネットワーク)によるエンコード部分に加え,後段の視覚的顕著性に基づく視線予測モジュールと,今回新たに提案する視覚的注意移動予測モジュールによるデコード部分で構成され,最終的に両方のモジュールからの出力を統合ネットワークで統合することで視線位置の予測マップが得られるというもの。
この技術は,一人称視点映像解析の研究で用いられている標準ベンチマークデータセットを利用した評価実験により,最新の既存の視線予測手法と比較して,提案手法がより高い精度で視線位置を予測できることが確認された。
研究グループではこの技術について,ものづくりの現場における技能の伝承や,自閉症スペクトラム障害の早期スクリーニング,自動車運転時の運転手の視認行動分析など,広く人の行動のセンシングと解析に関わるさまざまな分野での活用が期待されるとしている。