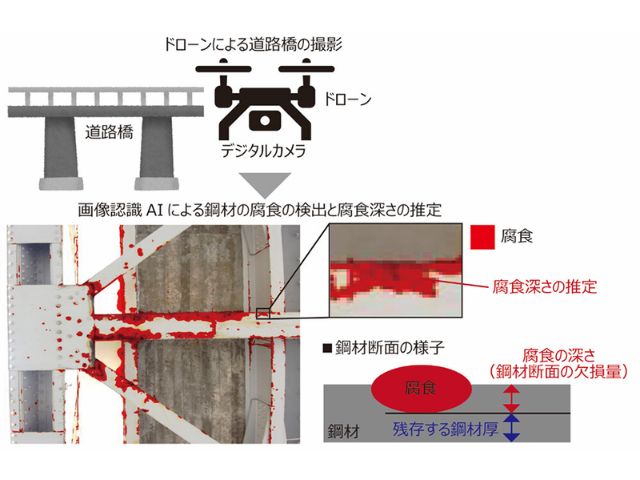
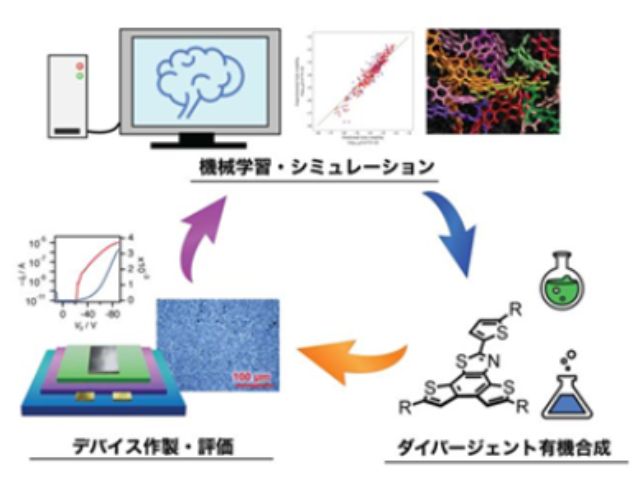
 富士通研究所は,少数のデータしか学習に使用できない場合でもディープラーニングによる物体検出を可能とするAI技術を開発した(ニュースリリース)。
富士通研究所は,少数のデータしか学習に使用できない場合でもディープラーニングによる物体検出を可能とするAI技術を開発した(ニュースリリース)。
近年,様々な分野でAIによる作業の自動化に向けた取り組みが行なわれており,例えば,医療分野では,診療画像の分析に異常個所などの物体検出をAIで自動化することなどが望まれている。
診療画像から特定の被写体を切り出す物体検出は,ディープラーニングを用いることが一般的だが,精度を出すためには学習させるための数万枚規模の正解データ付き画像が必要になる。しかし,正解データは専門知識を持つ医師しか作成できないため,大量入手は困難だった。
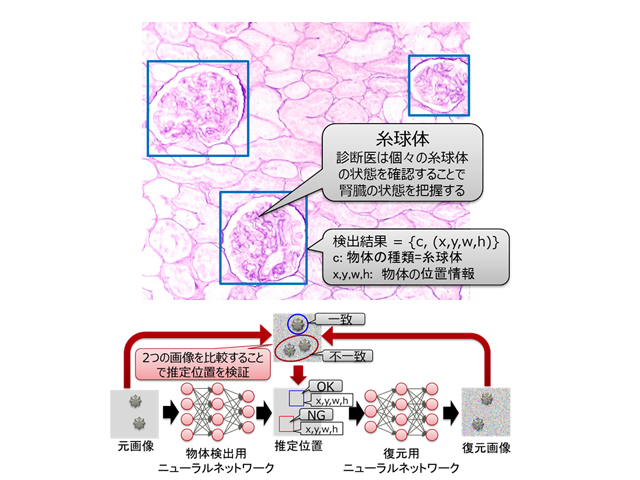
今回,物体検出ニューラルネットワークが出力する推定位置を元画像に復元する技術を開発(特許出願済み)し,元の入力画像と復元画像の違いを評価することにより,精度よく物体位置が推定された正解データを大量に作成でき,物体検出の精度を向上させた。
開発した技術を,京都大学との共同研究で取り組んでいる,腎生検画像からの糸球体の検出に適用し,評価した結果,正解データ付き画像50枚と正解の無い画像450枚を使用した実験で,同数の正解付き画像のみを使用した従来の教師あり手法に比べ,見逃し率10%以下の条件下で2倍以上の精度向上が認められたという。