 東芝は,通常のカメラ(可視光カメラ)で撮影した画像から,不規則に積み重なった物体の個々の領域を高精度に推定するAIを開発した(ニュースリリース)。
東芝は,通常のカメラ(可視光カメラ)で撮影した画像から,不規則に積み重なった物体の個々の領域を高精度に推定するAIを開発した(ニュースリリース)。
物流現場における自動化が進む中,倉庫内の荷物の搬送のみならず,荷降ろしやピッキング等の作業もロボットによる自動化が進められており,こうした物流ロボットの市場は,2030年度に,2020年度の約8倍の1,500億円規模になると予測されているという。
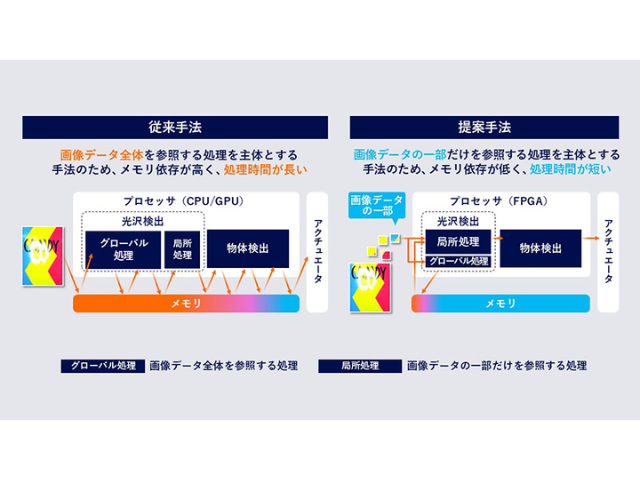
荷物の領域の特定には3次元センサーを用いた手法がある。奥行きの測定に優れているため重なり合う荷物の領域を高精度に特定することができるが,センサーのコストと事前学習のために必要となる3次元データの収集負担が高いという課題がある。
それに対し,通常のカメラを使用する技術が注目されているが,コスト・効率と精度はトレードオフの関係にあり,荷物同士が大きく重なった画像においてはAIが1つの物体であると誤認してしまう危険性があった。
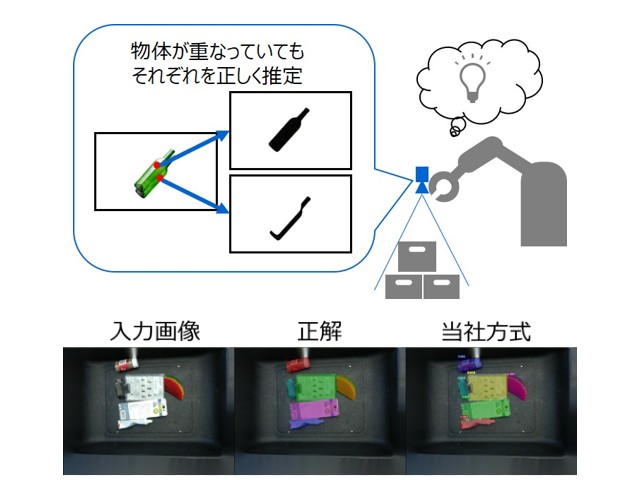
そこで同社は,物体の候補を点で推定する物体領域抽出方式を開発することで,乱雑に積み重なり荷物同士が大きく重なっているような状況においても,通常のカメラで上から撮影した画像から個々の荷物の領域を高精度に推定することに成功した。
従来の物体領域抽出技術は,まず,画像内に含まれる各物体を長方形で囲み,物体の領域の候補に挙げる。次に,その長方形内に含まれる物体の領域を画素単位で推定することで,個々の物体の領域として認識する。しかし,荷物同士が大きく重なっていると物体を囲む長方形も大きく重なり,1つの物体であると誤認してしまう問題があった。
今回開発した方式では,まず事前学習をしたニューラルネットワークを用いて,画像内の画素ごとに,物体の特徴を示す特徴値を求める。同じ物体に属する点であれば似た特徴値を,違う物体に属する点であれば異なる特徴値を出力する。次に,似た特徴値となった画素同士をまとめ,その中の代表点を物体の候補点とする。最後に,その候補点に対する物体の領域を画素ごとに推定する。
従来方式と比較してより微小な範囲を物体の候補点として捉えるため,上下に重なる2つの物体においても1つの物体としてまとめて捉えることなく,それぞれの領域を正しく推定することができるという。これらの技術をベースとしたAIの開発により,荷物同士が大きく重なっていても,上から撮影した画像から個々の荷物の領域を高精度に推定する。
このAIを,公開データを用いて実証実験をしたところ,推定精度を従来方式から45%改善する世界トップの性能を達成したという。同社は,本AIを組み込んだ荷降ろしロボットを2021年度に市場投入するとしている。