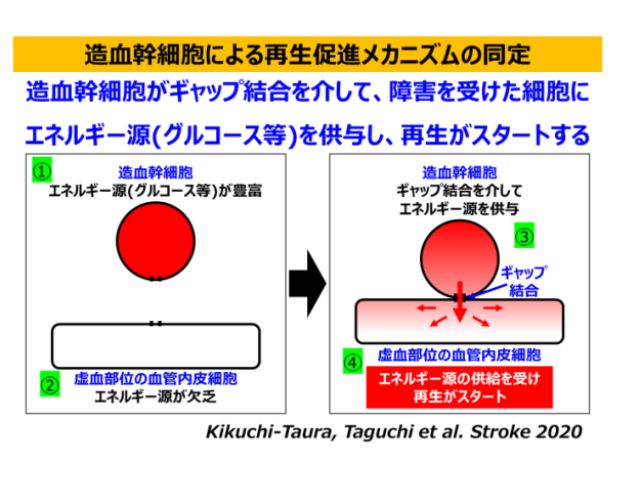
筑波大学と東京医科大学は,あらかじめ取得した患部の3次元CTデータを,術中のX線透視画像上に全自動で正確に重ね合わせる技術を開発した(ニュースリリース)。
整形外科手術ではX線透視画像を頻繁に使用するが,術中に,2次元情報である画像から患部の3次元形状を正しく認識することは難しい。
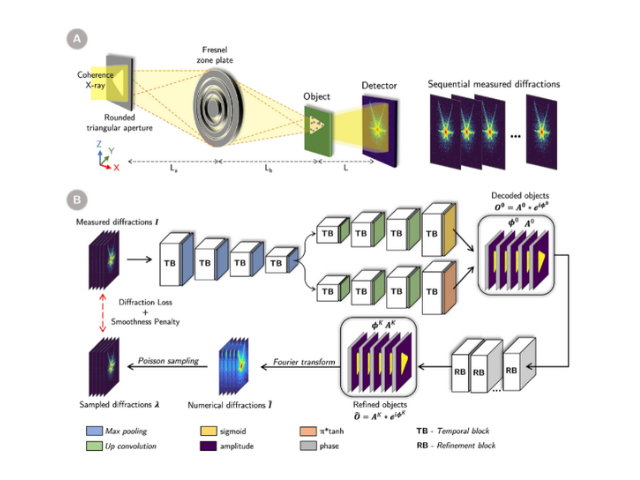
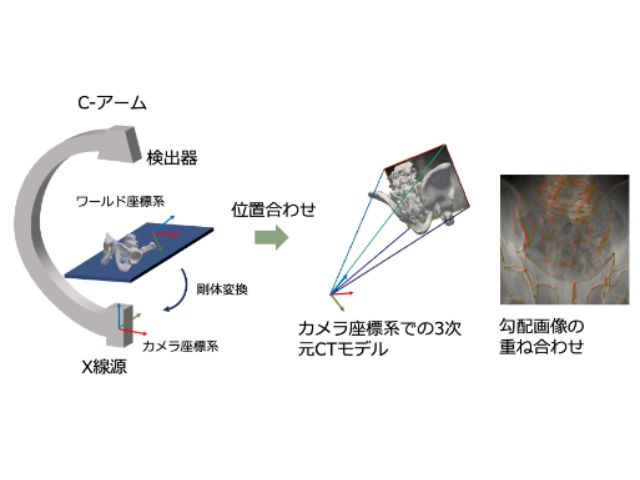
研究グループは,術中に用いる撮影カメラの光学中心と画像中の画素を結ぶ直線と,術前にCTスキャンで取得した3次元モデル(CTモデル)との交点で,シーン座標を定義し,その座標系で3次元点群とその観測位置の密な対応関係を自動的に取得可能な手法を考案した。また,この手法により獲得した対応点情報と深層学習を組み合わせることで,局所画像に対しても高精度な重ね合わせに成功した。
具体的には,X線画像からその対象物体の表面のシーン座標を回帰するモデルを開発した。この方法は,畳み込みニューラルネットワーク(CNN)を用いることで,推定するシーン座標を入力した画像の各画素と対応させる点が特徴となっている。
先行研究における位置合わせ手法では数箇所の対応しか作れないのに対し,この手法では密な対応が作れる。ここで,シーン座標系は3次元CTデータにおいて定義されているため,X線画像を撮った際に,その画像とCTデータの相対的な関係を求めることができる。
これによって明示的にランドマーク点のアノテーションを行なう手間が省かれ,さらに,骨形状が写っている限り対応点が得られるため,ランドマーク点を含まない局所画像についても重ね合わせができるようになる。
実験では,患者のCTデータからシミュレーションで生成したX線画像を使って,シーン座標を回帰する深層学習モデルを学習させた。その際,さまざまな撮影姿勢を設定した他,実際のX線画像のような見た目を再現するモデルDeepDRRを用いた。
その結果,シミュレーション画像でのテストでは,推定された位置姿勢と実際の位置姿勢には平均で3.88mmの誤差が確認された。また,10mm以下の誤差を重ね合わせの成功基準とした場合,失敗率は平均で11.76%にとどまった。また,シミュレーション画像で学習したモデルを実際のX線画像に適用したところ,画像上の誤差9.65mmの精度で重ね合わせができた。
研究グループは,この手法で得られた重ね合わせを初期値として,X線画像のシミュレーションと実際のX線画像の差分を最小化するように最適化を実行することで,さらなる精度向上が期待できるとしている。