科学技術振興機構(JST)課題達成型基礎研究の一環として、産業技術総合研究所 生命情報工学研究センター主任研究員の津田宏治氏、東京工業大学大学院情報理工学研究科 計算工学専攻准教授の瀬々 潤氏、理化学研究所統合生命医科学研究センターチームリーダーの岡田眞里子氏らは、従来に比べて格段に高い精度で誤発見の確率を示す検定値(P値)を計算するアルゴリズム(手順)を開発した。
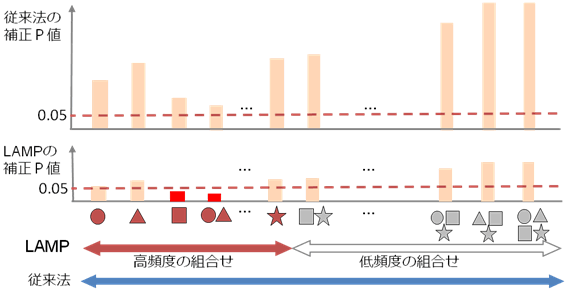
自然科学で得られるデータ量は増加の一途をたどり、これらを有効に解析できる方法が望まれている。しかし、従来の統計検定手法は観測できる対象が増えれば増えるほど、発見の基準を厳しくしなくてはならない。その結果、観測対象が増えたのに、科学的発見が減るという奇妙な現象「ビッグデータのパラドックス」が起きる場合がある。特に、複合的な組み合せ因子に対して極めて保守的な検定値(P値)を出すことが多く、有意義な実験結果が不当に低く評価されることがあった。
本研究グループでは、超高速アルゴリズムの技法を用いて、従来法より、格段に精度の高いP値を算出する新手法を開発した。この手法を、乳がん細胞株の増殖・分化に関与している転写因子の研究に利用したところ、既存の遺伝子発現データから新たな組み合わせ因子を発見することに成功した。
開発した手法を用いれば、これまで見過ごされてきた組み合わせ因子の発見が可能になる。本成果は、物理学、医学、化学など、全ての実験科学に貢献するものであり、今後世界中で広く利用されることが期待される。
詳しくはこちら。