1. はじめに
高度に発展し続けている情報化社会の進展は,常に信号処理技術,そしてそれを支えるハードウェア技術の進化を要求し続けている。ただし,IoT(Internet of Things)機器の増大,Connected X(Xには,Car,Health など様々入る)の進展,AIの爆発的な普及により,単体としてのハードウェアの進歩が追い付かず,「並列化」がその進化をささえる一つのキーワードとなっている。CPU(Central Processing Unit)やGPU(Graphic ProcessingUnit)などはマルチコア化し,さらには,チップレットと呼ばれる複数のチップを集積化する技術も近年注目されている,そして,一つのサーバには,それらが複数導入されることでさらに並列化をしている。そして,拠点内にはそのサーバが複数台並んでいる。しかし,一つの拠点内に設置するサーバ数は,土地,電気,セキュリティ等の問題から限界がある。そうすると,次の並列化のアイテムとして地域的に離れた場所にある拠点同士をつなぎ連携して処理をする「分散コンピューティング」が注目されてくる。本特集では,この分散コンピューティングにシリコンフォトニクスがどう貢献できるかを筆者および他の寄稿の著者が参画するプロジェクトを例にあげながら議論する。
2 分散コンピューティングに向けた問題点と解決策
前述したように,地域的に離れた場所に設置されている拠点を結ぶ「分散コンピューティング」を行う場合,いくつか問題がある。まず,遅延である。光ファイバを信号が伝搬する場合,当然光の速度による遅延が存在する。しかしながら,より深刻な問題は,現状のネットワークにおいては,電気スイッチが介在するため,光ファイバの物理的な遅延を遥かに上回る遅延が発生する。これによりリアルタイムな連携処理ができないことになる。そのため,従来の分散コンピューティングでは,あくまで相互に関係の少ない処理を行う(サーバ同士の通信をなるべく行わなくて済む)設計がされている。また,それぞれの拠点は,まったく同じ規模とは限らず,ある時刻に受け持っているジョブの数,規模も異なる可能性がある。その時に,同じ規模のジョブをリクエストしたとしても,うまくいかないことは容易に想像が可能であろう。また,サーバ内のメモリ帯域と大きく異なるネットワーク速度では,やはりローカルとリモート間での不均衡が起こってしまう。
以上より,これらの問題を解決するためには,
⑴ ネットワーク中において電気スイッチを介さず直接光スイッチを介して「多対多」でつなぐこと
⑵ また,多対多のネットワーク帯域を接続するサーバの能力によって「可変」できること
⑶ 最大10 Tbps 程度の帯域をトランシーバが有すること(もちろん帯域があっても消費電力が高ければ意味がない)
が挙げられる。加えて,仮にこれらが整ったとしても,そもそもこれらを使いこなすミドルウェア,ソフトウェアがなければ,その本質的な能力を発揮できない。
そこで我々は,先導研究を経て,2021年度から本格研究として,「異種材料集積光エレクトロニクスを用いた高効率・高速処理分散コンピューティングシステム技術開発」プロジェクトを国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の支援のもと行っている(https://www.nedo.go.jp/activities/ZZJP_100123.html, https://www.petra-jp.org/outline.html)。参画機関としては,技術研究組合光電子融合基盤技術研究所(PETRA),㈱ノーチラス・テクノロジーズ,日本電気㈱を実施者として,再委託・共同研究実施として,産業技術総合研究所,東京科学大学,東京大学,慶應義塾大学,北海道大学,大阪大学,名古屋大学,法政大学である。 このプロジェクトは,異種材料集積シリコンフォトニクスという革新的技術からミドルウェア・ソフトウェア技術という必要技術を完全網羅したプロジェクトという極めて挑戦的な取り組みである。
3. 分散コンピューティングとシリコンフォトニクス
図1 に,プロジェクトの概要図を示す。前述した項目に対して,「多方路エラスティックネットワークアーキテクチャ」を提案している。これは,サーバ間を光スイッチを介して複数で接続し,その帯域を各サーバの状況に応じて400 Gbpsを単位粒度としてその倍数で可変できるようにする。これにより,遅延量は分散コンピューティングの中でいち早い社会実装を必要とするリレーショナルデータベース(RDB)のリアルタイムレプリケーションなどで必要となる<10 msを達成することが可能となるとともに,各サーバのリソース状況に応じて待ち行列理論に基づく最適帯域で通信を行うことで,全体としての処理パフォーマンスを最大化できる。これを導入した場合のネットワーク全体の状況モニタ・自動制御するアルゴリズムの開発をまず行う必要がある。加えてこのようなネットワークができたとしても,これを活かしきるミドルウェア,ソフトウェアがなければならない。残念ながら従来のRDBにおいては,処理コアの拡大に対して,ある一定以上で飽和,または劣化する可能性があり,本プロジェクトでは,メニーコアに対応するために開発された国産RDBであるTsurugi をベースに,多方路エラスティック光ネットワークで活躍しうる拡張技術を新たに開発・導入することとした。なお,このような速度の場合,ファイバ分散や光速度による遅延により,距離の制限は受ける。そのため,本プロジェクトでは首都圏などの経済圏をカバー可能な100 kmをその適用範囲と考えているが,将来,中空ファイバの全面導入などが行われれば,その距離制限は大きく伸びると考えられ,そのようなファイバ開発をぜひ期待したい。
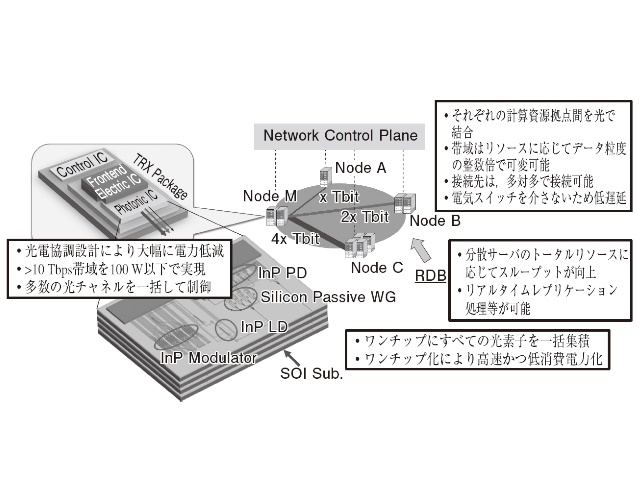
さて,このネットワークに必要となるトランシーバであるが,必要な要求性能として,まず400 Gbps粒度で10Tbps 程度までの帯域可変が可能であることが挙げられる。遅延に関しては,たとえエラー訂正等の技術を用いたとしても,RDBで必要とされる遅延上限に比べれば十分小さいため,問題にならない。
10 Tbps を実現するために,仮に現在の技術のトランシーバであっても,並列化すれば実現可能であるが,その場合,数百Wの消費電力となり,ネットワークカードで許容できる消費電力を超える。この先,現在の技術の延長で消費電力低減を待ったとしても,大きな消費電力を占めるデジタル信号処理回路の電力低減も大きくは期待できず,各光素子の消費電力もこれまでの研究者の不断の努力によりあまり余地が残っていない。また,並列化によるトランシーバの相当な大型化は避けられない。つまり,何らかのブレークスルーで大きく設計を変えなければ,マルチテラビットを超える広帯域,低消費電力かつ小型なトランシーバは実現できないのである。
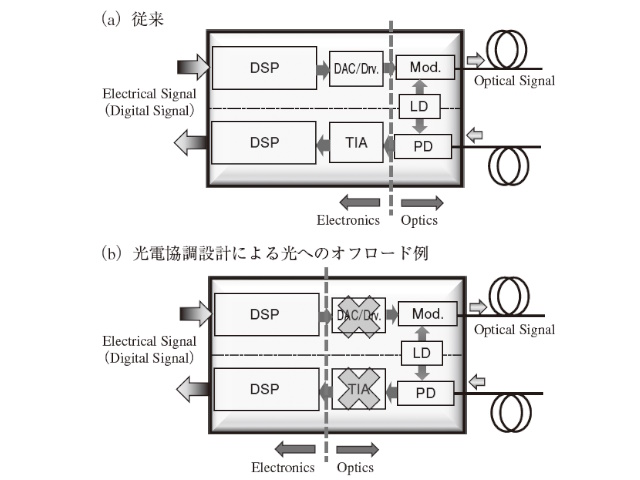
これに対して我々の提案は光集積回路を導入するとともに,電気回路と光集積回路の設計において光電協調設計を行うことである。図2 には,光電協調設計による効果を示している。従来は,電気回路と光素子はそれぞれ別に設計するため,必ず責任分岐点を明確にする必要があり,その境界には明確なルールが設定されていた。しかし,光素子を取りまとめて光集積回路とし,その直近に電子回路を配置し,2 つの回路の設計を協調して行うことによって,目的に対して「最適」な構成をとれることになる。例えば図2(b)に示すように,「電力」の最適化を考えた場合,従来構成では比較的大きい電力を消費していたデジタルアナログ変換器(DAC)やドライバ回路,トランスインピーダンスアンプ(TIA)などを光集積回路の中にその機能を移管するオフロードを行うことによって,取り除くことが可能となる。
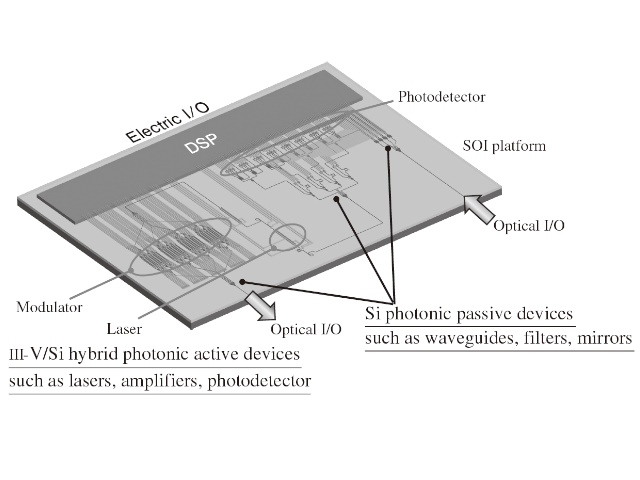
また,光集積回路の導入は光電協調設計を可能とするだけでなく,並列化を含む大量の素子の集積による小型,ワンチップ化や,これに伴う温度制御器の縮小による消費電力の低減など,複数の効果をもたらす。ただし,従来のシリコンフォトニクスでは,光源や増幅器などは実現できず,今後の高速化の観点からも制限が加わる。そのため,我々は図3 のように異種材料集積による光集積回路を導入する。これにより,光源,増幅器,変調器,受光器などで「最も性能が高い材料」を選ぶことができ,設計自由度を大幅に向上させることができる。
4. 本特集の構成
以上の内容について,詳細を各著者に寄稿していただいた。まず,RDBの観点から光技術の重要性,そして多方路エラスティックネットワークアーキテクチャ,光トランシーバ,異種材料集積回路およびその作製・測定と順を追って紹介いただいた。最後に,さらなる>10 Tbps時代に向けた大学の取り組みを述べていただいた。どうぞお楽しみいただきたい。
謝辞
本稿および次に続く本特集寄稿で用いられている成果もしくは成果の一部は,(国研)新エネルギー・産業技術総合開発機構(NEDO)(JPNP16007)の支援を受けた。プロジェクト遂行にあたり日頃ご支援いただく,PETRAおよび光産業技術振興協会事務局の皆様に感謝する。
本号の購入はこちら